Googleフォームでメールアドレス事前入力済みのフォームを自動送信で送る
背景
Googleフォームを参加登録などに利用していて遭遇するトラブルの1つは,入力してもらったメールアドレスが間違っていることやパソコンメールが受け取れないアドレスでの登録です。こちらから連絡ができずにどうしようもない状態になる場合もあります。
このような事態を防ぐためには,メールアドレスを2回入力してもらうという方法や仮登録としてメールアドレスを入力してもらい,仮登録したメールメールアドレスに本登録フォームを送るという方法があります。パソコンメールを受け取れないメールアドレスへの対応を考えると後者の方が良いため,後者をGoogleフォームとGoogle app scriptで実装してみます。
実装例
以下のようなフローを想定しています。なお,申し訳ないのですが,ある程度,Google app scriptの知識をお持ちな方を対象としているため,「トリガー」などの説明は省略させていただきます。
- 参加者は仮登録フォームからメールアドレスを入力し申込み
- メールアドレス欄に仮登録されたメールアドレスが既に入力された本登録フォームを用意
- 仮登録されたメールアドレスに,上記の本登録フォームのURLを含むメールを自動送信
まず,仮登録フォームと本登録フォームを用意します。
仮登録フォームの作成
仮登録フォームはメールアドレスを収集するだけで良いので,シンプルにメールアドレスを聞く項目だけにしておきます。ついで,仮登録フォームの回答を記録するGoogleスプレッドシートを作成します。このシートは,仮登録フォームの「回答」タブの右上の緑色のボタンから作成できます(下図)。
仮登録フォームを記録するスプレッドシートのIDもメモしておきます。以下の□の部分です。
https://docs.google.com/spreadsheets/d/□□□□□□□□□□□□□□□□□□□□□□□□/
本登録フォームの作成
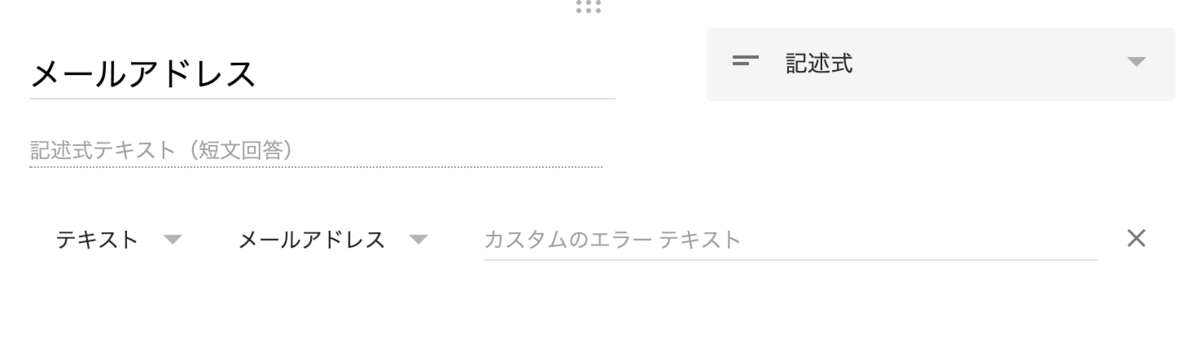
次に,本登録フォームを作成します。本登録フォームの形式はそれぞれ独自のものになるかと思いますが,フォームの項目にメールアドレスを入力する欄を作成しておきます。ここが重要ですが,Googleフォームの設定で自動的に作られるメールアドレス欄ではなく,自分で「記述式」項目としてメールアドレスを入力するようにしておきます。「記述式」の質問を作成し,「回答の検証」から「テキスト」と「メールアドレス」と設定しておくと良いでしょう。
次に本登録フォームの右上の3点リーダーをクリックして,「事前入力したURLを取得」を選び,メールアドレスの項目に適当なメールアドレスを入力します。そして,リンクの取得を選びます。

そうすると,メールアドレスの項目に先ほど入力したアドレスが事前入力された状態の本登録フォームのURLがコピーされます。このURLにはQueryパラメータとして,事前に項目に入力される内容が含まれています(&entry〜)。以下のような感じです(○○○○○はGoogleフォームのIDです)。
https://docs.google.com/forms/d/e/○○○○○○○○○○○○○○○○○○○○○○○○○/viewform?usp=pp_url&entry.743877729=abc@abc.com
このURLのメールアドレス部分を仮登録フォームで送信されたメールアドレスに変更し,変更したURLを自動送信すれば目標の達成となります。
Google app scriptの作成
これを踏まえて,仮登録フォーム(Googleフォームの方)のスクリプトエディタを開き,以下のようなGoogle app scriptを書きます。
function sendForm(){ var sheet = SpreadsheetApp.openById('□□□□□□□□□□□□□□□□□□□□□□□□'); //このフォームの回答を記録するスプレッドシートのID var regiSheet = sheet.getSheetByName("フォームの回答 1") //登録情報のシートの読み込み var lastRow = regiSheet.getDataRange().getLastRow(); //記録の最終行を取得 var mailAdress = regiSheet.getRange(lastRow,3).getValue(); //メールアドレス var formID = "○○○○○○○○○○○○○○○○○○○○○○○○○"; //本登録フォームのID var preFillEntry = "entry.743877729="; //本登録フォームの事前入力済みしたい項目名(=までを入力) var formURL = "https://docs.google.com/forms/d/e/"+ formID + "/viewform?usp=pp_url&" + preFillEntry + mailAdress; var mailTo = mailAdress; var mailSubject = "本登録フォームをお送りします"; //メールの件名 var senderAdress = "差出人のメールアドレス"; //差出人のメールアドレス var senderName = "差出人名"; //差出人名 var bodyText = "研究に参加いだたいている方へ\n\n以下のURLをクリックし,本登録をお願いいたします。\n"+formURL; //メール本文 MailApp.sendEmail(mailAdress, mailSubject, bodyText); //メール送信 }
最後に仮登録フォームのトリガーとして,「フォーム送信時」に上記のsendFormを実行するように設定すればOKです。 実際の運用では,申込前の説明や仮登録フォームの送信後などで,本登録用メールが届かない場合は別のメールアドレスなどで再度申込をするようアナウンスすることも必要でしょう。
注意点など
なお,このコードでは,メールの送信はGoogle app script(Gmail)で行っていますが,応募が多数行われる場合では送信数制限が厳しいため,sendGridなどを利用して送信した方がよいでしょう。また,複数人から同時申込に対するLock処理も入れた方がよいです。
参考
Googleスプレッドシートの質問紙(アンケート)処理をR(dplyr)で行う
最近,Googleフォーム&Googleスプレッドシートで質問紙調査を行う機会ができ,Googleスプレッドシートの処理をdplyr + stringiで行ったので,そのメモです。 dplyrはtidyverseパッケージに含まれるので,tidyverseをインストールしておいてください。
質問紙調査でよくあるパターン別にまとめてみます(随時追加していく予定です)。
まず,Googleフォームで質問紙を行った際にどのようにGoogleスプレッドシートに出力されるかを考慮しないといけません。 基本的に,Googleフォームの質問項目への回答はGoogleスプレッドシートに以下のような形で出力されます。
- 参加者1行で,各質問項目が1列で出力される
- 質問項目の1行目は質問項目で,2行目からは参加者の選択肢
- 質問項目は質問文すべてが1セルに出力される(例えば,「問1. 現在の気分を教えて下さい」という質問は,この質問文がそのまま出力される)
- 参加者の回答は選択した選択肢文が出力される(例えば,「5.どちらでもない」を選択すると,この選択肢文がそのまま出力される)
つまり,ほとんどのデータが文字型で出力されるため,分析にあたっては多くのデータは数値型に変換することが必要となります。 また,変数名も質問文になっていて,冗長なので簡便な名前に変更する方がよいです(例えば,尺度名+項目番号でCESD1〜CESD20など)。 さらに,逆転項目処理もざっとやってしまいたいということがあります。
まとめてみると,dplyrをつかって主に以下の作業をしたいわけです。実際はこれに追加でα係数の算出なども行うこともありますね。
- 質問項目文のままの列名を尺度名+項目番号へ変更
- 選択肢を数値に変換
- 逆転項目処理
- 尺度ごとの合計点の算出
なお,実際はパイプ(%>%)で連続でやる方が効率的です。 以下のコードについて間違いや改善点があればご指摘いただけると嬉しいです。
はじめに
データはirisを使います。質問紙のデータではないですが,処理自体はできるでそのままやります。
列名の変更
列名(1列だけ)の変更
renameで簡単にできます。
library(tidyverse) dat <- iris dat <- rename(dat, S = Species) head(dat, 3)
実行結果
Sepal.Length Sepal.Width Petal.Length Petal.Width S 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa
列名(複数列)の変更
複数の列を一括で連番を与えて変更する例です。 ちょっと特殊なやり方かもしれませんが,selectは列を選ぶと同時に列名を変更でき,その時に複数列を持ってくると変更する列名+連番にすることができます。
そこで,変更したい列を取得して列名を連番で変更した上で,さらに残りをeverything()で持ってきます。 コードでは,列番号の1列目から3列目をvar1〜var3に変えています。列番号で指定しているのは,Googleスプレッドシートだと列名(変数名)が質問項目文そのままなので,列名での指定がかなり面倒なためです。 これを尺度ごとに実行することで,尺度名+項目番号に変更できます。
selecetを使っていますが,renameかその派生形を使って,もっとよいやり方はありそうな予感・・・。
library(tidyverse) dat <- iris select(dat, everything(), var = 1:3) head(dat,3)
実行結果
var1 var2 var3 Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa
データの変換
文字列を数値に変換
質問紙では,「まったく当てはまらない」〜「非常によく当てはまる」というような選択肢から回答してもらうことが非常に多いです。 Googleフォームでは選択肢をそのまま出力するので,「1. まったく当てはまらない」などといった選択肢にしておけば,最初の1文字目を取得すればOKなのですが,場合によっては数値を当てにくい場合もあります。 そこで入力されているデータに応じて,数値に変換する必要があります。
mutate_atを用いて一括で変換が可能です。mutate_atはvars()に変数名,list(~ )でvarsで指定した変数に対して,list内の処理を行えます。 前はlist(~)ではなく,funs()だったようですが,list(~ )を用いることが推奨されています。
ここでは,case_when()という合致する条件ごと処理を行う関数を実施しています。 例えば, . == "setosa" ~ 1で,当該データがsetosaだったら1に変換という意味です。 ちなみに.(ピリオド)は当該データを表しています。
この例では,varsは1変数だけですが,ここに複数の変数を入れることで一括で変換できます。
library(tidyverse) dat <- iris dat <- mutate_at(dat, vars(Species), list(~case_when( . == "setosa" ~ 1, . == "versicolor" ~ 2, . == "virginica" ~ 3, ))) head(dat,3)
実行結果
Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 1 2 4.9 3.0 1.4 0.2 1 3 4.7 3.2 1.3 0.2 1
データの1文字目だけを残す
前述したようにGoogleフォームで,「1. まったく当てはまらない」とした場合には数値の部分だけ(つまり1文字目)だけを残す必要があります。この場合はmutate_at()とstringiパッケージのstr_sub()で複数の変数で1文字目だけを残せます。 str_sub()は指定したデータの何文字目から何文字目までを取ってくる関数です。
この例では,文字列の1文字目を持ってきていますが,「1. まったく当てはまらない」などの場合は,1文字目を持ってきて数値に変換したいので,list(~as.numeric(str_sub(.,1,1)))と書くと良いかもしれません。
なお,上の例と同様にvars()には複数の変数を指定できます。
library(tidyverse) library(stringi) dat <- iris dat <- mutate_at(dat, vars(Species), list(~str_sub(.,1,1))) head(dat,3)
実行結果
Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 s 2 4.9 3.0 1.4 0.2 s 3 4.7 3.2 1.3 0.2 s
逆転項目処理
尺度によっては質問項目に逆転項目が含まれます。その場合には逆転項目の逆転処理(数値を逆にする)が必要になります。 よく知られているように「(選択肢の最大値 + 1) - 逆転項目の値」を行うことで逆転項目の処理ができます。
今回は,逆転項目処理を一括で行いつつ,新たに逆転項目処理をした変数(○○_R)を作成するコードにしてみました。新しい項目として作成するのは,当該項目に上書きすると,逆転処理をしたかどうかがわからなくなる可能性を減らすためです。
ここでもmutateとmutate_at()が活躍します。
1項目だけの逆転項目処理
4からSepal.Widthを引いたSepal.Width_Rを作成します。
library(tidyverse) dat <- iris dat <- mutate(dat, Sepal.Width_R = 4-Sepal.Width) head(dat,3)
実行結果
Sepal.Length Sepal.Width Petal.Length Petal.Width Species Sepal.Width_R 1 5.1 3.5 1.4 0.2 setosa 0.5 2 4.9 3.0 1.4 0.2 setosa 1.0 3 4.7 3.2 1.3 0.2 setosa 0.8
1項目だけの逆転項目処理
4からvars()内の変数の値を引いた,各変数_Rを作成します。
library(tidyverse) dat <- iris dat <- mutate_at(dat, vars(Sepal.Width, Sepal.Length), list(R = ~4-.)) head(dat,3)
実行結果
Sepal.Length Sepal.Width Petal.Length Petal.Width Species Sepal.Width_R Sepal.Length_R 1 5.1 3.5 1.4 0.2 setosa 0.5 -1.1 2 4.9 3.0 1.4 0.2 setosa 1.0 -0.9 3 4.7 3.2 1.3 0.2 setosa 0.8 -0.7
合計得点の作成
合計点の算出はmutateで簡単にできます。
library(tidyverse) dat <- iris dat <- mutate(dat, total = Sepal.Width + Sepal.Length) head(dat,3)
実行結果
Sepal.Length Sepal.Width Petal.Length Petal.Width Species total 1 5.1 3.5 1.4 0.2 setosa 8.6 2 4.9 3.0 1.4 0.2 setosa 7.9 3 4.7 3.2 1.3 0.2 setosa 7.9
終わりに
もっと詳しいことを知りたい方は以下の書籍が参考になります。
Rで重回帰分析の3Dプロット(交互作用あり)を描画
はじめに
重回帰分析の3Dプロットを描画したいという場合があります。 できれば,交互作用をいれた場合といれない場合でも描画したいです。 rglパッケージを利用して,グリグリと動かせる3Dプロットで描画します。
rglパッケージをMacで利用する場合はX11のインストールが必要です。 使用したデータセットはtreesです。
交互作用なし
library(rgl) df <- trees fit <- lm(Volume ~ Girth + Height, df) df$pred <- predict(fit) Girth <- seq(min(df$Girth),max(df$Girth),len=100) Height <- seq(min(df$Height),max(df$Height),len=100) plot.df <- expand.grid(Girth=Girth,Height=Height) plot.df$z <- predict(fit,newdata=plot.df) library(reshape2) z <- dcast(plot.df,Height~Girth,value.var="z")[-1] open3d(scale=c(1,1,0.2)) points3d(df$Girth,df$Height,df$Volume,col="blue") surface3d(Girth,Height,as.matrix(z),col="gray",alpha=.2) apply(df,1,function(row)lines3d(rep(row[1],2),rep(row[2],2),c(log(row[3]),row[4]),col="lightblue")) axes3d() title3d(xlab="Girth",ylab="Height",zlab="Volume")
交互作用あり
library(rgl) df <- trees fit <- lm(Volume ~ Girth * Height, df) df$pred <- predict(fit) Girth <- seq(min(df$Girth),max(df$Girth),len=100) Height <- seq(min(df$Height),max(df$Height),len=100) plot.df <- expand.grid(Girth=Girth,Height=Height) plot.df$z <- predict(fit,newdata=plot.df) library(reshape2) z <- dcast(plot.df,Height~Girth,value.var="z")[-1] open3d(scale=c(1,1,0.2)) points3d(df$Girth,df$Height,df$Volume,col="blue") surface3d(Girth,Height,as.matrix(z),col="gray",alpha=.2) apply(df,1,function(row)lines3d(rep(row[1],2),rep(row[2],2),c(log(row[3]),row[4]),col="gray")) axes3d() title3d(xlab="Girth",ylab="Height",zlab="Volume")
プロットの例
左側が交互作用なし,右側が交互作用ありです。交互作用ありだと,捻れた面になっているのがわかります。

参考
Google Apps Scriptで「スプレッドシートから」の「フォーム送信時」トリガーが重複する問題
タイトルがすべてですが,以下のサイトを参考に経験サンプリングをやってみることにした際に,重複問題が起きました。なお,こちらの環境や設定,またはGoogleの仕様変更に伴う問題だと考えられるため,スクリプトそのものには原因はないと思います。
こちらのスクリプトの概要だけ述べると,参加者が登録用のGoogleフォームから登録を行うと,prepareSheetという関数が起動するという流れになっています。prapreSheetは(登録フォームの回答が記録される)スプレッドシートのスクリプトとなっています。正常動作では,登録フォームが送信されると,メールが送信されたり送信準備したりという関数になっています。
生じた問題は,1回(1人)の登録でこの関数が重複して起動するという問題でした。Google apps scriptでは,関数を起動するトリガーとして色々なものが設定できますが,prepareSheet関数は「スプレッドシートから」&「フォーム送信時」に起動するというトリガーを設定します。そうすることで,フォーム送信されるごと(=参加登録があるごと)に関数が起動するというわけです。どうやら重複の問題の原因は,このトリガーが1回の登録で数回起動しているということでした(トリガーのログで複数起動を確認)。同様の問題は以下でも報告されています。
解決策として↑のサイトと同様に,prepareSheet関数だけをフォームのスクリプトに移動させました。具体的には,スプレッドシートのスクリプトエディタからprapreSheet()をまるごとをコピーして,フォームのスクリプトエディタにペーストします。そして,一番上の一行を書き換えるだけです。
修正前
var sheet = var sheet = SpreadsheetApp.getActiveSpreadsheet();
修正後
var sheet = SpreadsheetApp.openById('シートのID');
シートのIDは登録フォームのスプレッドシートURLの"spreadsheets/d/xxxxxxxxxxxxxxxxxxxxxxxxx/"のxxxxxxxxxxxxxxxxxxxxxの部分です。
これで重複問題は解決して,うまく動きました。
Inquisitで1つの刺激に対して複数回の反応取得
Inquisitで,1つの刺激に対して複数回の反応を取得したい場合があります。例えば,顔の評価を測定する時に,顔Aについて魅力度,信頼性を測定したいというものです。なお,今回は画面上に「顔A+魅力度測定」を行った後に画面変移をして「顔A+信頼性」という流れを想定しています。「顔A+魅力度+信頼性」を1画面に収めるのであればそんなに複雑ではありません。
今回の条件を達成するために必要な要素は以下のようになります。
- 同じ刺激を画面を跨いでも利用できるようにする
- 同じ刺激に対して魅力度→信頼性の順番で評定項目を出す
ここでのポイントはlistの使い方です。listは配列に含まれる項目を1つ取り出す関数ですが,どのように取り出すかを細かく指定することができます。基本的には,取り出す順番(ランダムか順番か)と値をいつ更新するか(listを呼ぶ度に新しい値を取り出すか,同じblockではlistを呼んでも値は常に同じかなど)を決定します。例えば,1から3までの配列を作ったときに以下のようなパターンを作れたりします。
- 繰り返しなしランダム(2, 1, 3など)
- 繰り返しありランダム(1, 1, 3など)
- 同じBlock内では次の項目を呼び出さない(同じBlockではずっと同じ値のまま)
- 呼び出す度に次の項目を呼ぶ(毎回,値が更新される)
これを踏まえて,以下のようなコードで1つの刺激に対して複数回の反応取得が可能になります。
***
/ selectで/itemから選ぶ刺激番号を指定できるので,後ろで定義する配列変数(order)を指定する
***
<picture stimuliPicture>
/ items = stimuliSet
/ position = (50,35)
/ width = 35%
/ height = 35%
/ select = order
</picture>
***
各刺激
***
<item stimuliSet>
/1 = "1.jpg"
/2 = "2.jpg"
</item>
***
刺激の取得に関する配列を定義
/ items: 配列に含まれる数字を指定
/ selectionmode: 配列からどのように選ぶかを指定
/ selectionrate: 初期化(リストから次の変数を呼び出す)タイミングを指定
/ replace: 選んだものを戻すかを指定(ランダム時に同一のものを繰り返するかを決める)
***
<list order>
/ items = (1-2)
/ selectionmode = random
/ selectionrate = block
/ replace = false
</list>
<likert attractRating>
/ anchors = [
1 = "まったく魅力的でない";
5 = "どちらでもない";
9 = "非常に魅力的である"]
/ stimulusframes = [1=stimuliPicture]
/ numpoints = 9
/ anchorwidth = 3%
/ fontstyle = ("Meiryo",1.5%)
/ position = (50,60)
</likert>
<likert trustRating>
/ anchors = [
1 = "まったく信頼できない";
5 = "どちらでもない";
9 = "非常に信頼できる"]
/ stimulusframes = [1=stimuliPicture]
/ numpoints = 9
/ anchorwidth = 3%
/ fontstyle = ("Meiryo",1.5%)
/ position = (50,60)
</likert>
<block faceRating>
/trials = [1 = attractRating; 2 = trustRating]
</block>
<expt>
/blocks = [1-2 = faceRating]
</expt>
このコードを動かす際には「1.jpg」と「2.jpg」という画像ファイルがいるので,適当な画像ファイルをこの名前にしてスクリプトと同じフォルダにいれておいてください。コードを動かすと「1つの顔の魅力度を評定した後に,同じ顔の信頼性を評定する」というのが1ブロックの流れになります(block faceRating)。なので,あとは刺激の数だけブロックをexptで構成すれば良いわけです。
やや複雑になりましたが,faceRatingというblockではlistの更新をしない(/ selectionrate = block)ようにし,そのlist(order)を刺激の選択基準に用いることで,block内では同じ刺激を出し続けることができます。今回は評定(質問紙)を例にしましたが,list要素はうまく活用することで,刺激の呈示を制御することができます。
Rでwelchのt検定(t-test)と効果量をさっくり出す
タイトルの通りです。t検定と効果量を同時に出してくれるパッケージを探したんですが,見つけられなかったので作ってみました。t検定を出して,効果量を出して,というのも繰り返すとけっこう手間なので多少は楽できるかなと。 自分用なので細かい設定を省いています。もちろん,カスタマイズはご自由にどうぞ。また,Rで自作関数を作るのははじめてなので,間違いがあったら教えて下さい。
なお,cohen's dに関しては種類(計算式)があるので気をつける必要があります。例えば,within(対応のあるデータ)ではデータ間に相関があるので,それを考慮したcohen's dがあります。個人的には,within/betweenというデザインを越えて,効果量で比較したいことが多いのであまり計算しません。
実施には以下のパッケージが必要です。
effsize
#welch検定と効果量を1回で出す関数 t.test.es を定義 t.test.es <- function(x, y, t.paired = FALSE, es.ci = 0.95, es.paired = FALSE, rm = FALSE) { t <- t.test(x, y, paired = t.paired) es <- effsize::cohen.d(x, y, conf.level = es.ci, na.rm = rm, paired = es.paired) return(list(t,es)) }
t.test.es(x, y, t.paired, es.ci, es.paired, rm)
- x = データ1
- y = データ2
- t.paired = t検定に対応があるか(TRUE or FALSE; デフォルトはFALSE)
- es.ci = 効果量の信頼区間(デフォルトは0.95 = 95%)
- es.paired = 対応があるcohen's dにするか(TRUE or FALSE; デフォルトはFALSE)
- rm = 効果量算出時に欠損値を除外するか(TRUE or FALSE; デフォルトはFALSE)
例1(対応のないt検定)
library(effsize) #welch検定と効果量を1回で出す関数 t.test.es を定義 t.test.es <- function(x, y, t.paired = FALSE, es.ci = 0.95, es.paired = FALSE, rm = FALSE) { t <- t.test(x, y, paired = t.paired) es <- effsize::cohen.d(x, y, conf.level = es.ci, na.rm = rm, paired = es.paired) return(list(t,es)) } #t検定と効果量算出 t.test.es(x = iris$Sepal.Length, y = iris$Sepal.Width)
出力
[[1]] Welch Two Sample t-test data: x and y t = 36.463, df = 225.68, p-value < 2.2e-16 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: 2.63544 2.93656 sample estimates: mean of x mean of y 5.843333 3.057333 [[2]] Cohen's d d estimate: 4.210417 (large) 95 percent confidence interval: lower upper 3.802906 4.617929
例2(同じデータで対応のあるt検定)
library(effsize) #welch検定と効果量を1回で出す関数 t.test.es を定義 t.test.es <- function(x, y, t.paired = FALSE, es.ci = 0.95, es.paired = FALSE, rm = FALSE) { t <- t.test(x, y, paired = t.paired) es <- effsize::cohen.d(x, y, conf.level = es.ci, na.rm = rm, paired = es.paired) return(list(t,es)) } #t検定と効果量算出 t.test.es(x = iris$Sepal.Length, y = iris$Sepal.Width, t.paired = TRUE, es.ci = 0.95, es.paired = FALSE, rm = FALSE)
出力
[[1]] Paired t-test data: x and y t = 34.815, df = 149, p-value < 2.2e-16 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: 2.627874 2.944126 sample estimates: mean of the differences 2.786 [[2]] Cohen's d d estimate: 4.210417 (large) 95 percent confidence interval: lower upper 3.802906 4.617929
inquisit4でVASの実装
Visual Analogue Scale(VAS)は画像や顔の評定に用いられる測定方法です。アナログ(紙)で実施する場合には10cmの水平線を引いて,両端に測定値を置きます(例えば,嫌い〜好き)。評定対象に対して,最も当てはまる位置で直線にスラッシュを入れてもらいます。実験者は定規でスラッシュの位置を測り,それを点数とします。10cm = 100mmなので,0〜100の得点範囲になります。
実験・調査をする上でLikertではなくVASを使いたいという場合はけっこうでてきます。例えば,プレポストで同一の対象を2回評定する場合,LikertよりVASの方がよいでしょう。Likertでは値を覚えられていたり,わずかな変化を測定しにくいためです。 inquisitでもVASはslider要素を用いることで実装できます。コードの例としては以下です。
スライダーを作成
<slider s1>
/ range = (0,100)
/ required = true
/ caption = ("この画像について評定してください")
/ labels = ("嫌い", "好き")
/ slidersize = (40%, 3%)
/ position = (50%, 50%)
/ showticks = false
/ showtooltips = false
/ size = (60%, 5%)
/ defaultresponse = 0
/ required = false
</slider>
評定する画像
<picture picture1>
/ items = "1.jpg"
/ position = (50,30)
</picture>
スライダーを埋め込んだページを作成
<surveypage ratingPage>
/ questions = [1 = s1]
/ stimulustimes =[1 = picture1]
/ nextlabel = "次へ"
/ finishlabel = "終了"
/ nextbuttonposition = (65,70)
/ showpagenumbers = false
/ showbackbutton = false
</surveypage>
調査にページを入れる
<survey pictureRating>
/ pages = [1 = ratingPage]
/ showbackbutton = false
/ showpagenumbers = false
/ showquestionnumbers = false
/ finishlabel = "終了"
</survey>
slider独自の各要素の簡単な説明は以下の通りです。
- range = (x, y): xからyまでの得点範囲
- slidersize = (x, y): スライダーの大きさ
- caption = (""): テキストでの説明
- labels = ("x", "y"): 評定の両端のラベル
- showticks = true/false: 目盛りの有無
- showtooltips = true/false: カーソルを合わせるとでる説明
- defalutresponse = x: 初期値をxに設定
- required = true/false: 回答が必須かどうか
基本的に,VASでは目盛りを出さない方がよいのでshowticksやshowtooltipsはfalseがよいでしょう。なお,ラベルは直線の左右ではなく,両端の上にでます(説明が難しいのですが,いわゆる紙のVASとはレイアウトが異なります)。もし,直線の左右に出したい場合は,別途,textとして表示するしかありません。この場合,textとsliderの表示位置を合わせるが手間となります。
sliderの注意点として,WindowsとMacでデザインが異なる点があります。例えば,スライダーのカーソルはMacは丸形(○)ですが,Windowsでは長方形に似た形になっていたりします(inquisit4だけかもしれません)。
ここから,ややこしいのですが,上のコードはsurveyでの利用を想定していますが,実はinquisitではsliderは調査(survey)だけでなく実験(block)でも利用できます。inquisitのreferenceにはsurveyの要素として紹介されているので気がつきにくいのです。
blockで利用する利点として,同じsliderを繰り返し利用できる点にあります。どういうことかというと,調査(survey)でsliderを利用する場合には,基本的には評定対象1つにつきslider1つがセットになります。 例えば,画像A,画像Bがある時には,画像AとsliderA,画像BとsliderBを用意する必要があります。画像Aと画像Bの両方でsliderAを記述すると,最初の答えたスライダー位置が2回目もでてきます。具体的には,最初に画像Aに80と回答した場合には,画像Bの評定画面でスライダーの位置が80になってしまいます。刺激が少ない場合はこれでも良いのですが,例えば,画像100枚の評定を考えてみると,pictureとsliderのペアを100個コピペしなければいけません。手間はもちろんかかりますし,コードミスが生じやすいという危険なプログラミングになってしまいます(そもそもコピペの繰り返しをプログラミングといっていいのか?)。
一方で,blockで利用すれば,同じsliderを繰り返し用いてもdefaultresponseの値に毎回リセットされますので,100回繰り返す場合でも大丈夫です。
スライダーを作成
<slider s1>
/ range = (0,100)
/ required = true
/ caption = ("この画像について評定してください")
/ labels = ("嫌い", "好き")
/ slidersize = (40%, 3%)
/ position = (50%, 50%)
/ showticks = false
/ showtooltips = false
/ size = (60%, 5%)
/ defaultresponse = 0
/ required = false
</slider>
評定する画像
<picture pictures>
/ items =pictureSet
/ position = (50,30)
</picture>
<item pictureSet>
/1 = "1.jpg"
/2 = "2.jpg"
</item>
スライダーを埋め込んだページを作成
<surveypage pictureRatingTrial>
/ questions = [1 = s1]
/ stimulustimes =[1 = pictures]
/ nextlabel = "次へ"
/ finishlabel = "次へ"
/ nextbuttonposition = (65,70)
/ showpagenumbers = false
/ showbackbutton = false
</surveypage>
実験にページを入れる
<block pictureRating>
/ trials = [1-2= pictureRatingTrial]
</block>
この例では,2つの画像(1.jpg, 2.jpg)を用意し,それらをランダムな順番でそれぞれ評定してもらうという実験を想定しています。 参考になれば幸いです。